AI 음성 인식
음성 데이터의 기본
yc7764
2023. 5. 14. 19:17
소리의 3요소

- 공기의 밀도가 변하며 퍼져나가면서 소리가 발생하며 소리의 시간에 따른 밀도 변화를 파동(Wave) 또는 음파라고 함
- 파동 또는 음파의 모양을 파형(WaveForm)이라고 하며, 파동의 진동 수, 파장, 진행 속도, 진폭을 이용해 표현
- 소리의 3요소인 소리의 세기, 높낮이, 맵시에 따라 모든 소리를 구분할 수 있게 함
1. 소리의 세기(Loudness)

- 소리의 세기는 음파의 진폭(Amplitude)을 의미하며, 공기 분자가 얼마나 크게 흔들렸는 지를 나타냄
- 크게 진동하는 물체는 주변의 공기를 크게 떨리게 진동시켜 진폭이 큰 음파를 만들어 냄
- 진폭이 크면 소리가 강해지고, 진폭이 작으면 소리가 작아짐
- 데시벨(dB) 단위를 사용해 소리의 세기를 나타냄
2. 소리의 높낮이(음정, Pitch)
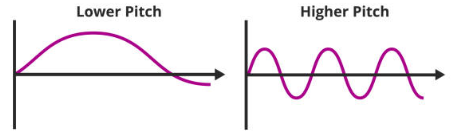
- 소리의 높낮이는 음파의 진동수를 의미하며, 공기가 얼마나 자주 흔들렸는 지를 나타냄
- 자주 진동하는 경우에는 높은 소리가, 적게 진동하는 경우 낮은 소리가 남
- 1초 동안 주기가 반복되는 횟수를 주파수(Frequency)라고 하며 주파수가 높을수록 진동의 속도가 빨라짐
- 즉, 주파수에 따라 소리의 높낮이(Pitch)가 결정되며, 헤르츠(Hz)를 사용해 주파수를 표현함
3. 소리의 맵시(음색, waveform)


- 소리의 맵시는 파동의 생긴 모양을 의미하며 소리의 진폭과 높낮이가 같더라도 맵시가 다르면 다른 소리로 느껴짐
- 소리를 발생시키는 물체의 모양과 진동을 일으키는 방법이 다르면 소리의 맵시도 달라지게 됨
음성 데이터


- 현실에서 입력으로 주어진 아날로그 음성 신호를 디지털 신호로 바꾸어 음성 데이터를 저장
- 소리가 마이크에 감지되면 전기신호로 변환되며, 마이크가 1개인 경우 모노(Mono, single-channel), 2개인 경우 스테레오(Stereo, multi-channel) 음성이라고 함
- 실제 소리는 연속적인 파형을 가지기 때문에 디지털 신호로 저장하기 위해 일정 간격으로 구분하는 작업을 수행하며 이러한 작업을 샘플링(Sampling)이라고 함. 즉 샘플링을 통해 연속치를 이산치로 변환해 저장
- 연속적인 값에서 1초 당 샘플링한 횟수를 샘플링 속도(Sampling rate)라고 하며 높을수록 음성 데이터의 음질이 좋음
음성 파일 형식
1. WAV(Waveform audio format)

- 윈도우에서 사용되는 표준 PCM 형식의 파일로 대부분의 음원 편집/재생 소프트웨어에서 지원
- 무손실, 무압축 방식으로 용량이 크며 원본 소스를 손실없이 저장 가능
2. FLAC(Free Lossless AUdio Codec)

- WAV 파일 형식보다 쉬운 파일 관리를 위해 탄생한 무손실 압축파일 형식
- WAV 파일 형식 대비 용량 40~50% 절감하지만 WAV나 FLAC이나 같은 규격을 가지고 있다면 포맷이 달라져도 정보 손실 없음
- FLAC 파일을 디코딩하는 과정에서 CPU 연산이 다른 포맷에 비해 적게든다는 장점이 있음
3. MP3(MPEG-1 / MPEG-2 Audio Layer -3)

- MPEG(1988년에 정의된 동영상 표준화) 오디오 규격에 맞게 개발된 손실 압축 포맷으로 인간이 듣지 못하는 부분을 제거하고 압축하여 용량을 작게 줄인 파일 형식
- MP3 파일 형식은 뛰어난 오디오 품질을 유지하며 PCM의 1/10 정도의 용량을 가져 가장 인기있는 파일 형식임
4. AAC(Advanced Audio Coding, M4A)

- MP3보다 뛰어난 음질과 압축률을 보이며 MP3의 한계인 320kbps과 48kHz보다 향상된 512kbps과 96kHz까지 지원
- 스트리밍 음원 서비스 및 유튜브 영상, 블루투스처럼 음원을 쪼개서 전송해야 되는 환경에서 탁월한 성능을 보임